Cite us as:
Hyejin Youn, Logan Sutton, Eric Smith, Cristopher Moore, Jon F. Wilkins, Ian Maddieson, William Croft, Tanmoy Bhattacharya, On the universal structure of human lexical semantics, Proc Natl Acad Sci USA doi: 10.1073/pnas.1520752113 [link]
How to build the network:
The full detail can be found [here] and the result [link]:
The key is dictionary translations and backtranslations!
We note that translations uncover the alternate ways that languages partition meanings into words. Many words are polysemous, i.e., they have more than one meaning; thus they refer to multiple concepts to the extent that these meanings or senses can be individuated. Translations uncover instances of polysemy where two or more concepts are fundamental enough to receive distinct words in some languages, yet similar enough to share a common word in other languages. The frequency with which two concepts share a single polysemous word in a sample of unrelated languages provides a measure of semantic similarity between them.
Figure below illustrates the construction with examples from two languages. Translating the word SUN into Lakhota results in wi and anpawi. While the latter picks up no other meaning, wi is a polysemy that possesses additional meanings of MOON and month, so they are linked to SUN in the network. A similar polysemy is observed in Coast Tsimshian where gyemk, the translation of SUN, also means heat, thus providing a link between SUN and heat. We write the initial Swadesh concepts (SUN and MOON in this example) in capital letters, whereas other concepts that arise through translations (month and heat here) are in lower case. We restrict our study to the neighborhood of the initial Swadesh concepts , so further translations of these latter concepts are not followed. The data are link and link
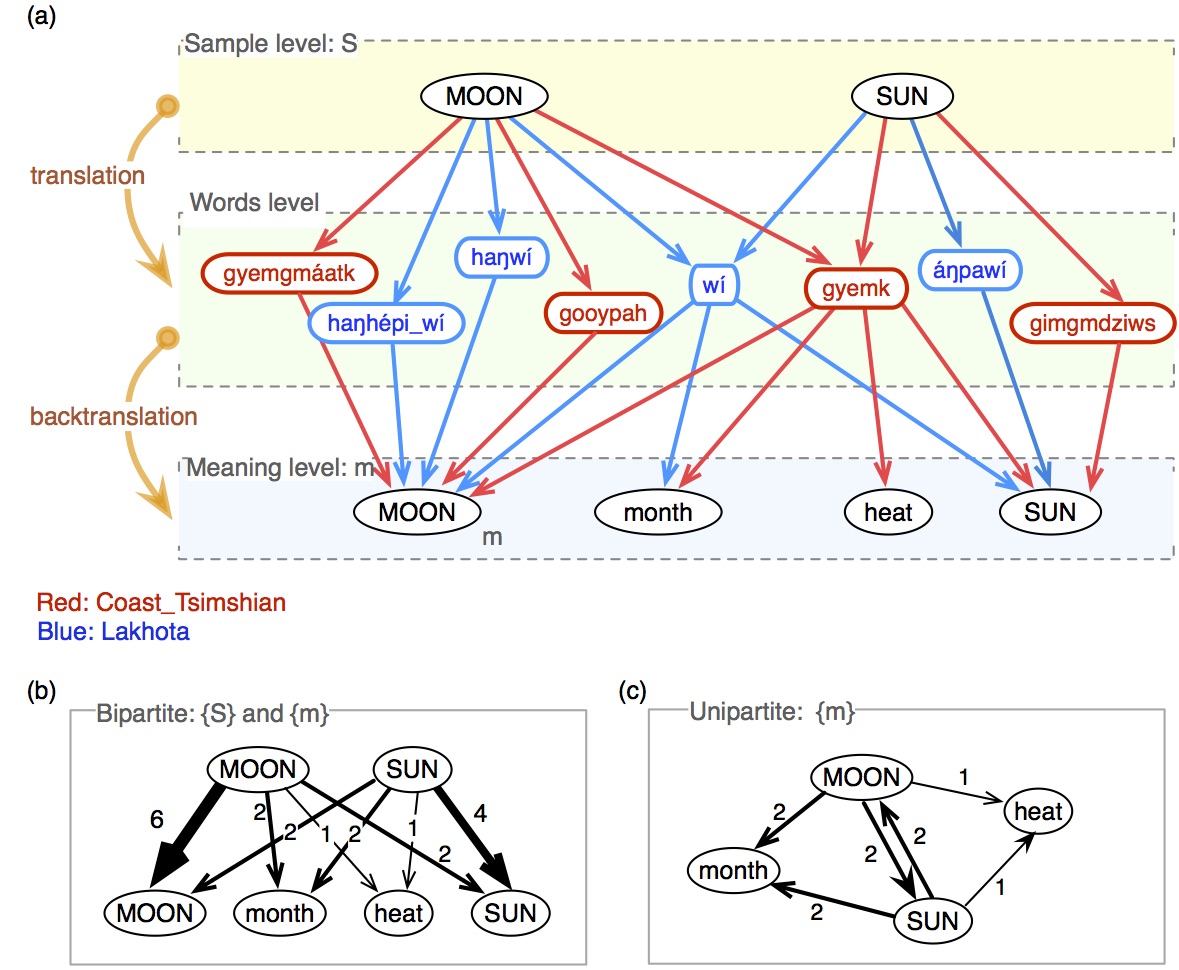
With this approach, we can construct a semantic network for each individual language (find here).
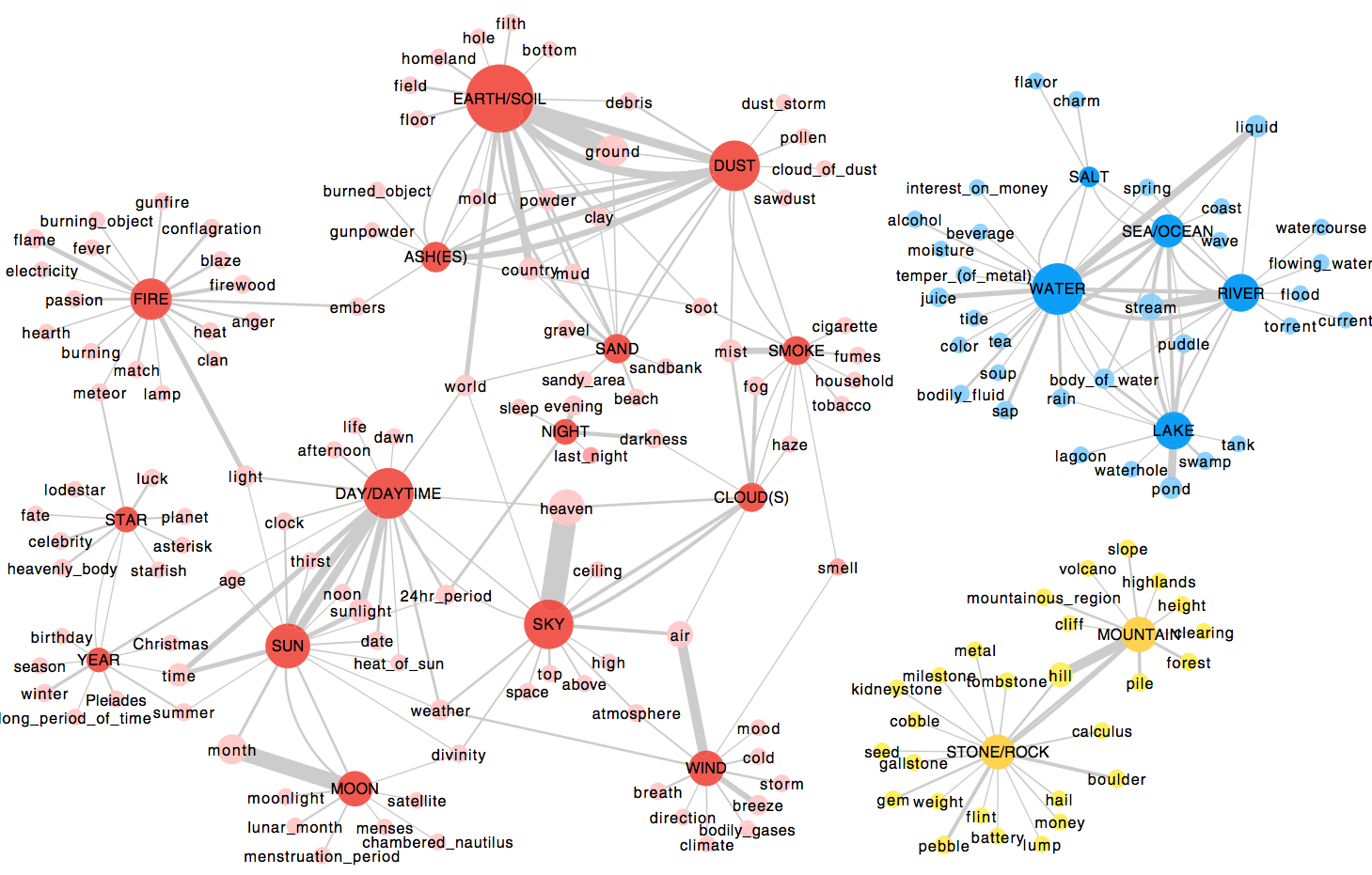
Universal structure? Really? How to find them
You may feel some commonality at work across the languages by exploring the webpage, but may not be able to put your finger on the universality.
The structures we discuss in this work are mainly mathematical structure (somewhat seen in the network representation, yet mostly hidden).
The mathematics we used to identify the universality are:
1) Mantel test: using commute distance between two nodes in a network (the expected number of steps it takes a random walker to travel from one node to another, and back). We then compare the Pearson correlation of the measured distances between empirical language groups and bootstraped random groups.
2) Hierarchical clustering tests: we transform our networks into a tree structure using spectral analysis. Then, well known metrics (triplet distance and Robinson-Fouldd metrics) test whether the networks of language groups are more similar than what we would expect by chance.
3) Kullback-Leibler: a standard measure of the difference between an empirical distribution and our theoretical prediction that we constructed in the paper. In this way, we can judge how good our theory is to the empirical evidence.
The details can be found [here].
Our hypothesis
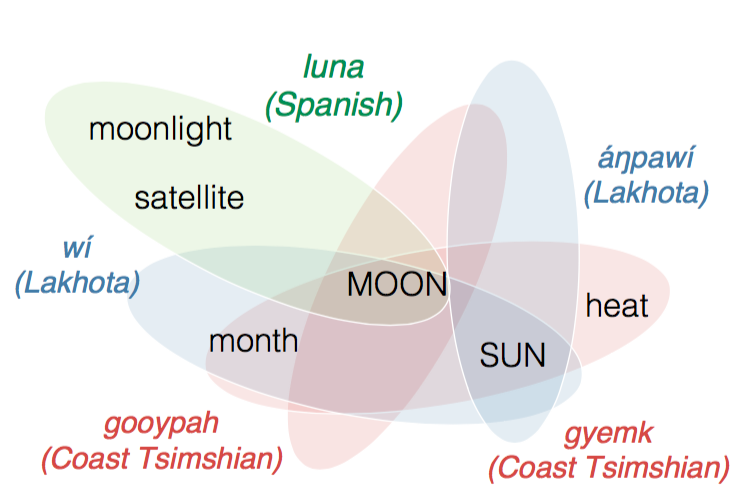
Figure below shows what is our hypothesis. This is a speculation we have how concepts are partitioned
by words (by labeling them). Hypothetical word-meaning and meaning-meaning relationships using a
subset of the data. In this relation, translation and back-translation
across different languages reveal polysemies through which we measure
a distance between one concept and another concept.
List of Languages
Notwithstanding
the vast and multifarious forms of culture and language,
most psychological experiments about semantic universality have
been conducted on members of Western, educated, industrial, rich,
democratic (WEIRD) societies, and it has been questioned whether
the results of such research are valid across all types of societies.
We chose an unbiased sample of 81 languages in a phylogenetically and geographically stratified way (see the figure below), according to the methods of typology and universals research. Our large and diverse sample of languages allows us to avoid the pitfalls of research based solely on "WEIRD" societies. Using it, we can distinguish the empirical patterns we detect in the linguistic data as contributions arising from universal conceptual structure from those arising from artifacts of the speakers' history or way of life.
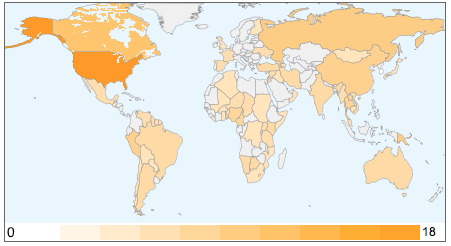
The below is the list of languages

In plain English




In Other languages
 in Finnish.
in Finnish.
 in Russian.
in Russian.
 in Italian.
in Italian.
 in Danish.
in Danish.
 과학동아
과학동아
.
Back to the webpage